在 2025 年云栖大会上,理想汽车CTO谢炎发表了主题为《车端推理系统的思考与展望》的演讲,围绕智能驾驶算法演进、算力瓶颈、AI计算架构革新及理想汽车的实践这几个维度分享了自己的观察和看法。以下是其演讲全部内容:
非常高兴回到阿里巴巴。当时请我来讲的时候,我其实不知道应该讲什么,因为如果讲云计算,我们跟阿里云在比较紧密的合作,在训练一侧,包括训练的这些资源和技术,讲云这侧可能有点班门弄斧,我就想讲一下车端。我们在做的一些思考和展望,还有一些实践。
我今天的分享就分这4部分,第一部分讲一下这个车端最重要的就是智能驾驶算法的演进,从演进,我们会看到这个计算会成为一个巨大的瓶颈,推理计算在车端,我们会重新思考一下 AI计算的架构,我们会进一步的我们会得到说,在观看回看历史的时候,看到数据流架构其实它是一个很好的解决方案,重新再回顾数据流架构的历史发展,最后分享一下理想汽车在这方这个方向上的一些实践和一些结果。
首先介绍一下车端智驾算法的演进,可能大家也都看到过,自动驾驶算法其实主要在过去大概10年主要分成三段,第一段是用规则算法,也就是感知规划模块,虽然局部的有用一些深度神经网络,但是它连在一起都是用这个人工规则来连在一起的,特别是像规划模块在很长时间都是规则制。
第二阶段,最近两年其实如果让神经网络自己学习,比人去教它,人去定义它,你应该迈左脚迈右脚,而是让它自己在数据里面学习会更高效,会学得更好,所以我们的技术就转化成了这个叫E2E,然后这边会加一个VLM,主要的还是E2E,意思就是说这个模型它自己学,我们数据从传感器输入到控制出来,其实人工干预非常少,基本上是把模型结构定义好,让它自己通过数据来学习,发现用一个视觉语言模型可以更好的让它有一些对世界的理解能力,这些理解可能也会输入到E2E的模块里面,得到一个更好的控制。
E2E加VLM的结果非常好,在过去一年多的时间里面,我们自动驾驶发展得非常快,很多地方大家说开得像老司机了,很多地方拐弯了,直行加速减速更接近于人类的体感,因为它就是模仿学习,它就是学习人类的一些动作行为。
今年开始, 其实从去年年底开始,就是我们在看 VLA+RL强化学习,VLA的话它跟端到端跟VLM有非常大的不同,它的主体主要就是L,然后V是做一个视觉信号的编码,然后输入到L让L来学习,然后最后通过diffusion来生成轨迹,这样的结构会更简单。
今天的技术发展其实是有一些争议的,L还要不要,早上我在主论坛的最后一趴,可能大家都走了,圆桌论坛上我稍微讲了一下,为什么我们会需要L?因为L我认为从除了技术原因,其实本质上一个技术原因,一个非技术原因。
技术原因,L是人类做泛化的基础。就是人相比于动物能够思考的更远更长更深,其实最大的区别在于人类会有语言。语言能力它不仅仅是一个交流工具,它其实是一个可以做cot的工具。
所以如果我们在自动驾驶里面,随着我们的能力越来越强,越来越像人,它在最后那段最后5% 10%,它需要解决越来越corner的case,你可能是没有办法仅仅靠收集数据,或者说仅仅靠在一个世界模型里面让它自己撞,能撞到的。概率非常低,实际上人不是这么学习的,人可能是基于一些基本的逻辑规则,可能就能推理出,但是那个规则它推理的时候,它不是用规则,是用神经网络,推理出我可能要做什么动作,我从来没遇到这个场景,但我也很好的能够处理,我们希望自动驾驶去获得这种长链路的推理能力,我们觉得这个能力是基于语言的,也不是说我就需要语言的token的输出或者输入,这个都是minor,都是相对次要的,本质原因是我们需要它的长推理能力。
第二个原因是心理的。它如果作为一个人类的司机,你希望它的思考的模式像人,你并不希望它是一个猴子学车学出来的,虽然它也知道红灯停绿灯行,但它并不具备跟你相同的世界观和价值观。你希望它跟你一样遇到一些比如说晚上路遇到路很窄的时候,虽然我能看得清楚,但我也知道害怕我应该减速,这些事情它没法靠规则,更没法靠说E2E你一条一条去教它,所以这些东西你希望这个模型是像人的。但像人的,你再往前推,你你怎么能让它更像人,更具备人类的世界观,我们今天找到方法其实就是语言模型,因为语言模型大语言模型学到了很多人类语料,它通过学习人类说话,其实学会的是人类的思考方式。这个是一步步推演过来的,我们认为语言提供了一个是长推理能力,带来的泛化、能力和它更像人的世界观,但是这里面离不开大语言模型的进一步进展。
语言模型如果在自动驾驶里发挥越来越大的作用,语言这一块发挥越来越大的作用会发生什么?我们知道语言模型有scaling law,就是模型越大,思考链路越长,你消耗的token越多,它的结果就越好,实际上你就能够推测得到我们在车端需要越来越强的算力,而且这个算力有可能按照我们现在的轨迹发展不是线性的,它是超线性的,它是指数型的,这个是个实际的,现在的硬件的发展速度,你看前几年,2017年到22年以前或者24年以前,其实发展得非常慢,车端的算力基本上大概在200到300Tops,int 8或者IP8。
然后你发现从25年开始,接下来的规划从thor,包括红色的是特斯拉,HW4到HW5,仅仅两年时间,它可能要翻6倍,它可能要把车端的算力从400Tops翻到2500,为什么?如果仅仅靠视觉它不需要这么做,原因是大家都发现我们需要把自动驾驶能够推到下一个level的话,你需要超级强大的算力,这个是远超以往。
所以你往往AI6看的话,你会看到更高。那么问题来了,如此快速的增长,车端能不能承受,一个成本能不能承受对吧?效率足不足够高,我们用现在的架构是不是能够支撑,我们会重新思考AI的计算架构,作为一家车企去抢处理器架构,这件事情好像有点超纲,但是我们还是做了。
我们看一下计算架构的演进趋势,我们回过来看的话,最左边是通用计算,大家都认为最早 CPU是单核单线程的,基本上非常符合人类的习惯,我一步一步做。然后碰到图形的时候,这时候老黄出来了,老黄说我要出更高效的处理图形,我要把三角形几万个几十万个几千万个三角形每个三角形做计算,同时快速的输出结果,我需要很多很多线程,但每个线程处理一个三角形,回过来我绕,这个方法也很好,这个方法让英伟达在图形计算掘到了第一桶金,然后到了AI计算,你发现pattern的不一样了, AI计算的 pattern计算模型它其实跟图形计算不太一样,图形计算是局部性非常好,我基本上一块三角形我就不停的在上面算,算颜色算光照,算各种参数。
AI计算你可能是大量的,一是数据规模更大,第二是大量的计算,比如llm的decoding,基本上数据进来算一次就走了,其实你用更大的cash是完全没有用的,AI计算有一点是适合GPU的,它也需要大量的thread,大量的线程,GPGPU其实是今天的目前的最优解,非常适合原因是thread多,但是这个是不是终极答案我们也一直在想,业界也很多在思考。
GPGPU在这个过程里面,老黄他们也是发展的,Nvidia也是继续在发展,它原来是在图形时代它主要是算标量,然后到GPGPU时代它主要算张量它加入了张量核,但是很可惜它的 programming,它的计算的本身的架构没有变,下面还是SMT,还是Shared Memory,还是共享内存,共享内存有一个问题,其实当你的并形度变高的时候,对Shared Memory压力是非常大的,大家会看到为什么现在内存带宽,HBM要求带宽越来越高?你这个压力都在这儿,就因为你的计算架构决定了你压力必须在存储这儿。
更本质一点讲,其实从CPU到GPU到GPGPU,本质上是冯诺依曼架构,冯诺依曼架构核心本质是程序主要关注的是计算不是数据,数据是第二等公民,计算是一等公民,当你到了AI了,你发现计算的算子没有那么多,但是你的数据的处理会变得很复杂,而且数据的处理会非常大量,所以所以实际上给我们的启发就是我们能不能做让编程者或者让程序更多的关注数据,而不是关注计算。实际上是有的。
最近有几篇论文,像Megakernel。想把小kernel合并成大kernel,好处就是你中间的数据不往外流。不往外流的原因就是你其实在人工的在handle数据如何流动不往外流,然后 CMU的Mirage Persistent Kernel也是它其实把它拆成一片一片更细粒度,也是在处理数据的流动,你关注这两篇,这两个工作里面关注都不是计算,关注的是数据,数据如何留,如何存储,我们在想,如果说是数据流比控制流更重要的话,我们可不可以设计一个架构,直接面向数据流控制。这个是我们的思考。
数据直接驱动计算,这个计算本身是没有顺序的,是数据驱动的,编程者或者说以后是 AI,更多的关注的是数据流动,而不是计算,然后能不能设计一个架构,能够最高效的来运行这种模式。其实这个历史上有人早就研究过了,这个并不是一个新的故事,其实在计算机刚刚开始不久,MIT就有一拨人就认为计算的本质可能是数据驱动,所以它们就是数据流的先驱,开创者是MIT的Jack B.Dennis,还有一个印度裔的科学家叫Arvind,它们当时设计的Data driving execution 就是用数据驱动来计算,它们把计算就是把这个程序把它展开变成一个数据流图,最早的工作它是一个静态图,只能静态展开,它没有动态能力,它不能支持循环,它不能支持迭代。Arvind和G.R. Gao也是我们大陆去MIT毕业的第一个博士生高光荣教授,它们想到的是tag token,把激发计算的token打标。
设计了一种memory model叫I-structure,这种I-structure它其实有点像后来的Java Object,就Java的栈上的这个对象是不可更改,引用可以改,它的特性就是不可更改,用来解决说你某一个算子它的输入和输出之间它可能有一些数据的重叠问题,共享问题。
90年到2000年,高教授它们做的工作是叫做Threaded Dataflow Architecture, 它把粒度原来在上一轮工作里面,就是Arvind的工作里面,其实每个计算都是一个非常小的算子,它把它放稍微放大一点,放到一个thread,提供了编程语言叫RC,这些工作都是因为在超级计算领域,所以不为大家所知。
再到2000年到2015年,其实它们开始发现 DSP其实也是一个天然的数据流场景,在DSP的基础上设计了叫Codelet/COStream/Fresh Breeze Memory Model,Codelet是一个计算模型,COStream是个编程模型,Fresh Breeze是个memory model,三个加在一起就能cowork。
从动态数据流机到线程化这个架构,其实就是指令集更小的粒度变成稍微粗一点的粒度,高教授它们又提供了编程模型执行模型和硬件架构要一起设计,右下角两张图是他们用作的超级计算机,一个叫Earth,一个是IBM 蓝基因的Cyclops64。其实也是follow架构就是说我大量的并行大量的同构计算和然后通过一个mesh bus(网络总线)连在一起,然后用compiler(编译器)去调度。
这里面我重点介绍一下从Codelet到COStream的发展, Codelet的刚才讲的是一个同构重合的并行架构,它可以无限扩展,因为它没有Shared Memory,所以它非常容易扩展。
进一步的在COStream在这个模型上面提供了程序编程语言,一个C like的编程语言,它把计算的描述变成算子,最小的是一个算子,但算子跟算子连在一起,你可以变成一个单入单出的composite叫做复合体,你可以进一步的把它变成数据流图,硬件架构可以放在RC或者Cyclops64,这个是之前的工作。
我们当时就想到这样的工作,我们其实也可以用在AI上,几个核心本质是不变的,一个编程抽象是不变的,执行的语义不变的,编译的流程是不变的,你无非就是说我把原来的一个数据变成张量对吧?我把这个算子变成AI算子,原来是一个DSP的算子变成AI算子。
接下来我就简单介绍一下。我们在这个基础上,我们自己做了一个车端的计算架构,这个计算架构其实比较follow刚才的思想,你看左边是SOC,右边是NPU,主要我们的设计主要在NPU里面,因为SOC里面无非就是一些前处理后处理的CPU Cluster,然后加一些IO在外面,还有内存访存控制器,NPU的架构里面其实是一个重合架构,然后加一个CCB,Central Control Computing Block它是用来做一些前处理后处理,不太适合非张量的计算。所有的每个class都是同构的,然后它们之间是用这是Mesh bus连在一起,同时我们也提供Ring Bus(环形总线)来做广播,这个是我们完全是我们独创的一个AI推理架构,目前国内没有这么做的。
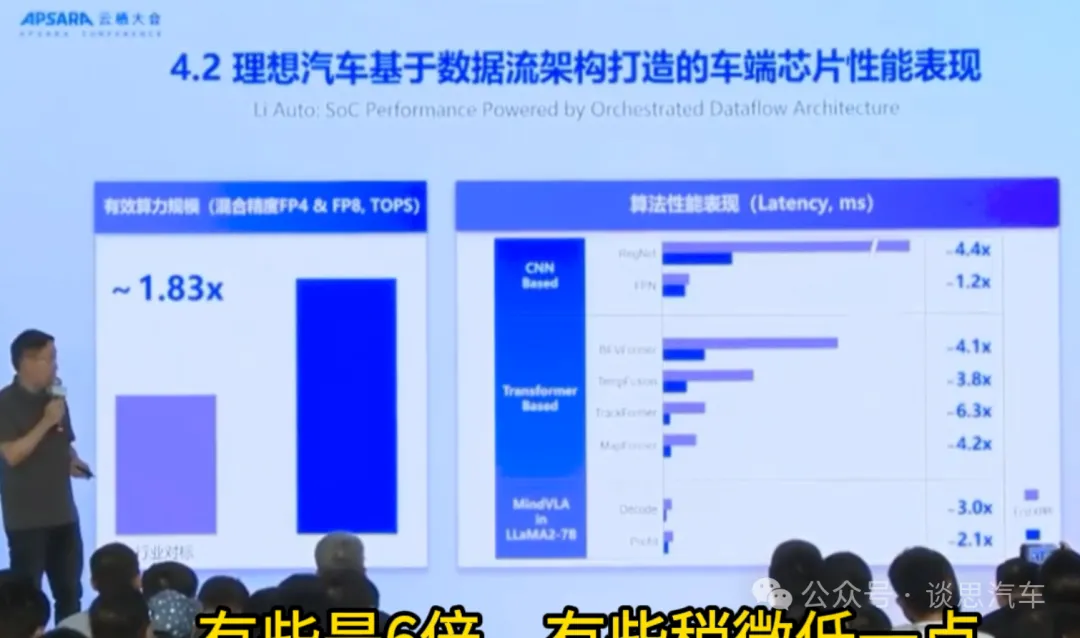
当然这个工作其实比较挑战的是编译器,因为它硬件结构比较简单,我们现在已经流片回来了,我们大概跟行业最好的今天的推理车端推理芯片比,我们大概可以性能是在IP4和IP8的上面大概是1.83倍,但是这个比较general,如果你把它分到一些具体的算子算法上,比如说视觉类的CNN的大概可以到4.44倍,其实大家面积差不多,我们跟业界行业能够买到的最好的芯片相比,我们在同等晶体管消耗差不多的情况下,我们可以做到4.4倍CNN,然后transformer base可以做到不同的,有些是4倍,有些是6倍,有些稍微低一点。然后在LlaMA2的7B上面大概是两倍到三倍,所以初步的效果还可以,编译器还是挑战,因为你要让编译能够非常高效的把你所有应用都用起来,但是这里面还涉及到很多编程模型和编译架构的设计。好,我的分享就到这里,感谢大家。
上一篇:高通在下一盘AI“大棋”
下一篇:SOA 在智能网联汽车的应用价值与挑战分析
- 热门资源推荐
- 热门放大器推荐
 非常经典的关于LLC的杨波博士论文
非常经典的关于LLC的杨波博士论文 INA2126E-250
INA2126E-250
- RDR-142 - 35W电源
- i.MX RT1060 Evaluation Kit
- 使用 Embedded Planet 的 5CEFA9U27 的参考设计
- DC1369A-D、LTC2258-14 演示板、14 位 65 Msps ADC、LVDS 输出、5-170MHz
- LT3990EMSE-5 12V 降压转换器的典型应用
- 使用 Analog Devices 的 LTC1148 的参考设计
- LT1377IS8 具有直接反馈的正负转换器的典型应用
- 使用 NXP Semiconductors 的 TL431AI 的参考设计
- LT8304IS8E 18V 至 80Vin、5Vout 隔离反激式转换器的典型应用电路
- LT3512EMS 演示板,单片式高压隔离反激式转换器 36V VIN 75V,VOUT = 5V @ 500mA

 ASM10DTBD-S664
ASM10DTBD-S664






 京公网安备 11010802033920号
京公网安备 11010802033920号